Kubernetes security contexts allow you to configure security options at the pod or container level. While some parameters are well understood, others can be more obscure and confusing. In this post, we’ll debunk myths about the allowPrivilegeEscalation option.
TL;DR—allowPrivilegeEscalation is a security hardening option, no less, no more. If you’re able to turn it off on your workloads as a quick win, by all means do so! Otherwise, it’s not something that will get you hacked by itself. If you’re not explicitly disabling it, you’re probably fine.
What is ‘allowPrivilegeEscalation’?
Ask any security engineer if your applications should be allowed to “escalate privileges”, and you’ll likely receive blank stares, confused looks, and perhaps even questions about your sanity.

Fortunately, there’s a misunderstanding here. While you’re asking:
Does it matter if I don’t explicitely set the “allowPrivilegeEscalation” flag to false?
… your security engineer is hearing:
Is it fine if my insecure Java application can escape its container and dance around our cluster like it’s 1999?
Great news! You both share at least one thing in common: neither of you has the slightest idea what the allowPrivilegeEscalation flag means—and honestly, who could blame you?
Common misconceptions about ‘allowPrivilegeEscalation’
Let’s get it out of the door: while turning off allowPrivilegeEscalation can be valuable, it’s a security hardening setting that you can leverage to increase security in containerized environments.
In particular, if you leave allowPrivilegeEscalation set to true (its default value):
- It will not magically allow unprivileged process in the container to escalate their privileges to root.
- It will not allow processes running inside the container to escape the container.
- It will not allow the pod to perform any sort of privilege escalation within the cluster.

“But Christophe,” I hear you ask, “what does it even do then?” Let’s first see an example of the type of attacks it does prevent. Then, we’ll dive into how container runtimes implement it.
‘allowPrivilegeEscalation’ in action
Let’s reproduce a scenario where a vulnerability allows an unprivileged process to escalate its privileges to root within a container. This can happen with kernel-level vulnerabilities such as DirtyCow, DirtyPipe, or CVE-2023-0386 in OverlayFS. We can also test an easier (but no less realistic): abusing a root-owned binary with the setuid bit set. First, let’s reproduce this scenario. Then, we’ll see how turning off allowPrivilegeEscalation prevents successful exploitation.
We’ll use the following program, which uses setreuid (as in “set real and effective user id“) and setregid to effectively escalate privileges to root. By design, this works only if the binary is owned by root and has the setuid bit set:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void) {
// Escalate to root
setreuid(0, 0);
setregid(0, 0);
// Spawn a shell
char* const argv[] = {"/bin/bash", NULL};
char* const environ[] = {NULL};
execve("/bin/bash", argv, environ);
}
gcc escalate.c -Wall -o /tmp/escalate sudo chown root:root /tmp/escalate sudo chmod +s /tmp/escalate
We can now use an unprivileged user to confirm that this vulnerable program allows us to escalate our privileges to root:
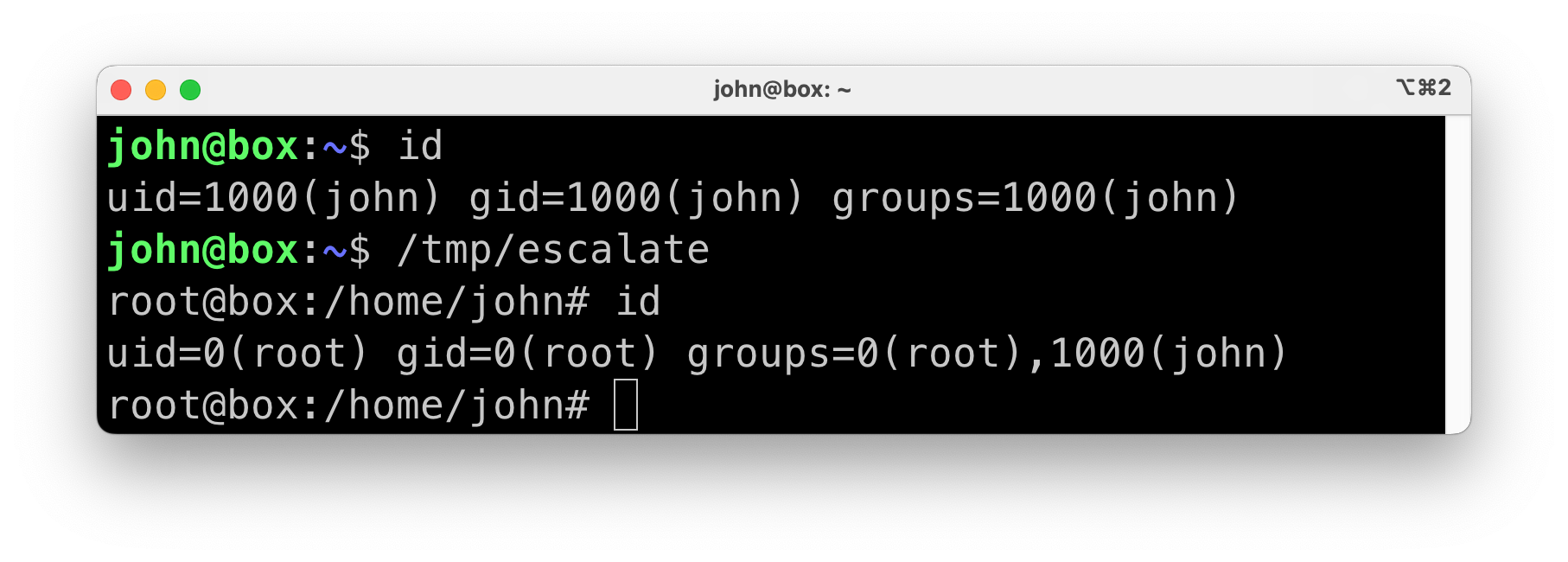
The following Dockerfile simulates an Alpine container image running an application as an unprivileged user, with the vulnerable binary inside it:
▸ Dockerfile (click to toggle)
FROM alpine:3.20 AS builder
WORKDIR /build
RUN cat > escalate.c <<EOF
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
int main(void) {
// Escalate to root
setreuid(0, 0);
setregid(0, 0);
// Spawn a shell
char* const argv[] = {"/bin/bash", NULL};
char* const environ[] = {"PATH=/bin:/sbin:/usr/bin:/usr/sbin", NULL};
if (-1 == execve("/bin/bash", argv, environ)) {
printf("Unable to execve /bin/bash, errno %d\n", errno);
}
}
EOF
RUN cat /build/escalate.c
RUN apk add --no-cache gcc musl-dev
RUN gcc escalate.c -Wall -o escalate
FROM alpine:3.20 AS runner
WORKDIR /app
COPY --from=builder /build/escalate ./escalate
RUN chown root:root ./escalate && chmod +s ./escalate
RUN adduser app-user --uid 1000 --system --disabled-password --no-create-home
RUN apk add bash
USER app-user
ENTRYPOINT ["sh", "-c", "echo Application running && sleep infinity"]
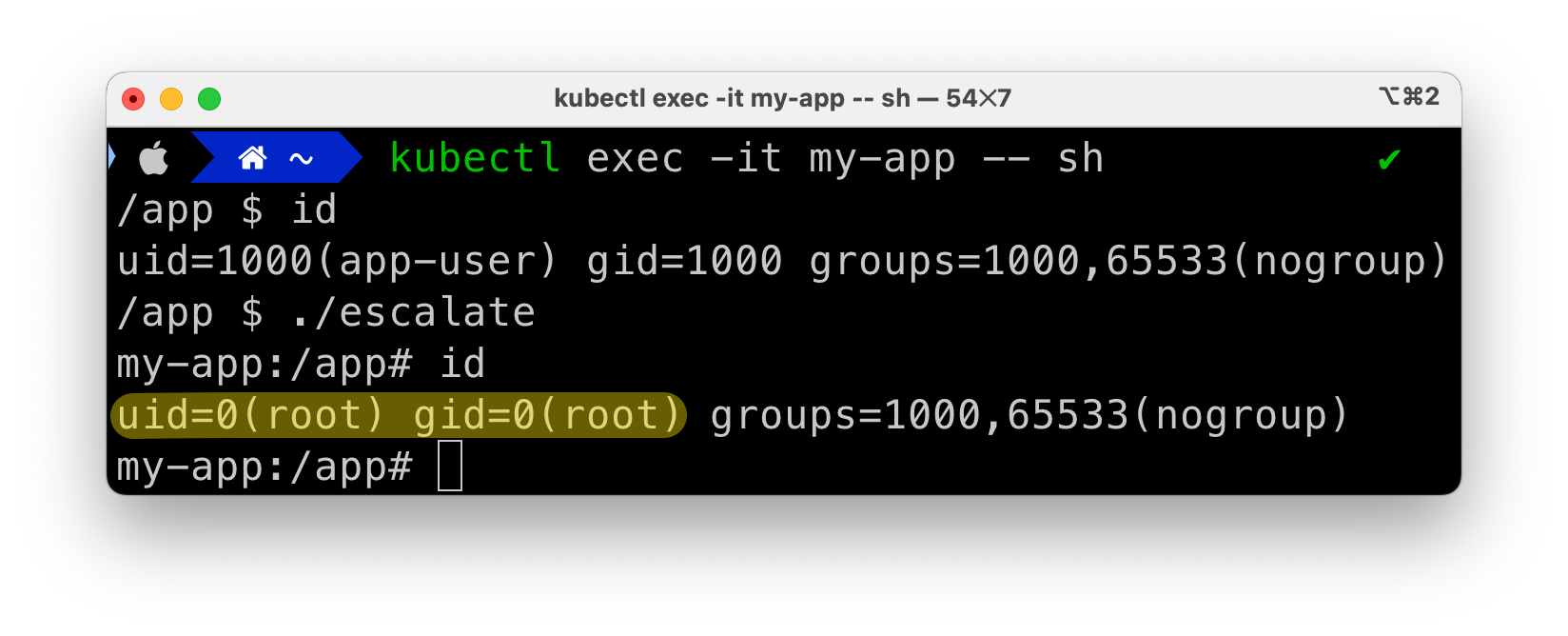
Let’s build it and run it in a Kubernetes cluster, explicitly turning on allowPrivilegeEscalation (even though it’s the default value):
# Build the image
docker build . -t my-app:0.1
# Create a kind cluster and run the image on it
kind create cluster
kind load docker-image my-app:0.1
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
securityContext:
runAsUser: 1000
runAsGroup: 1000
containers:
- name: my-app
image: my-app:0.1
securityContext:
allowPrivilegeEscalation: true
EOF
As expected, we’re able to exploit the vulnerability to escalate our privileges to root:
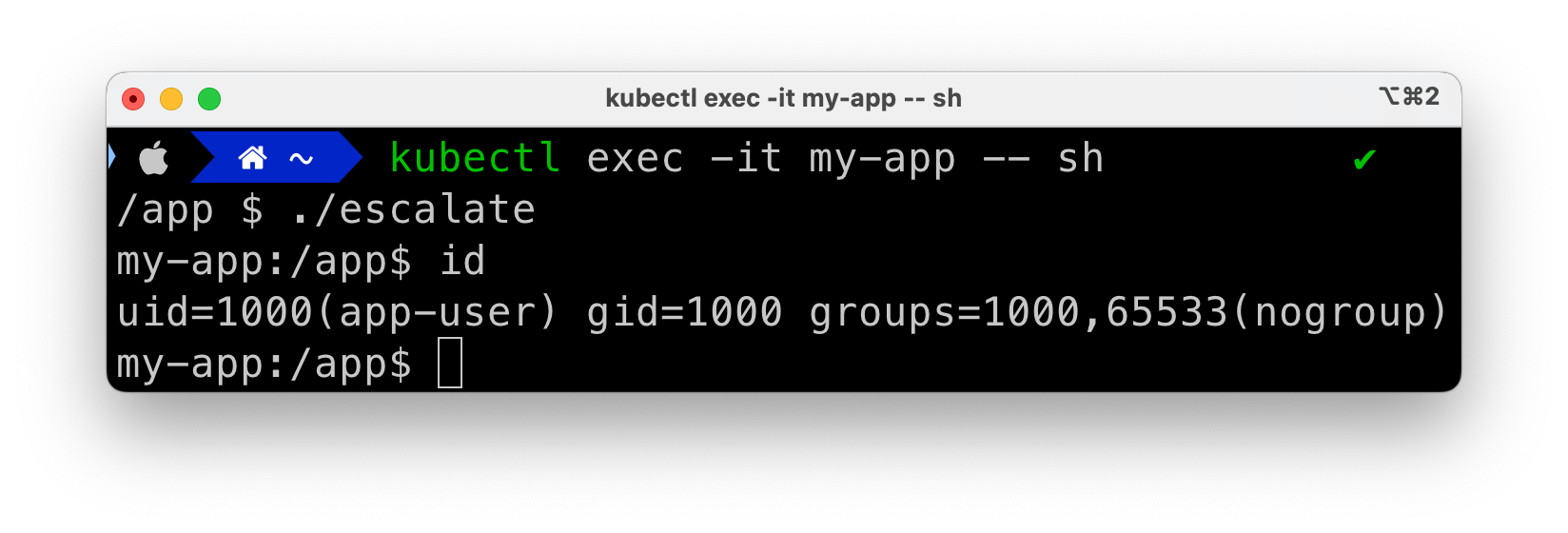
If we however start our pod with allowPrivilegeEscalation set to false, we get:
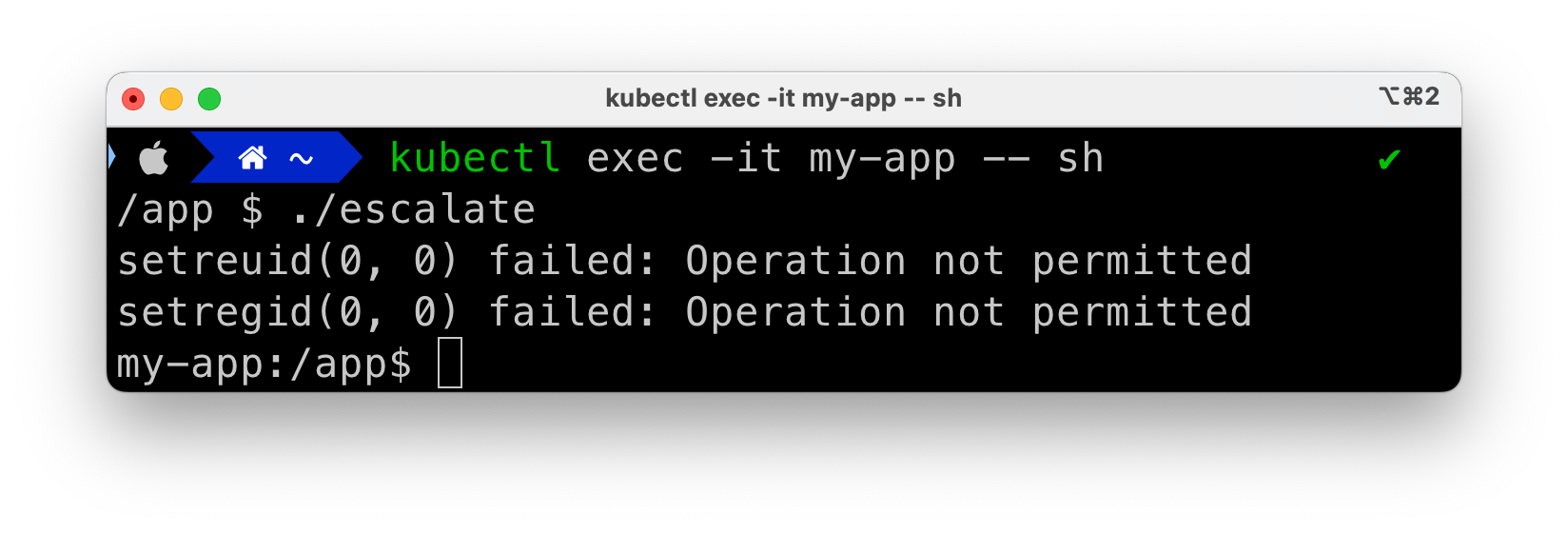
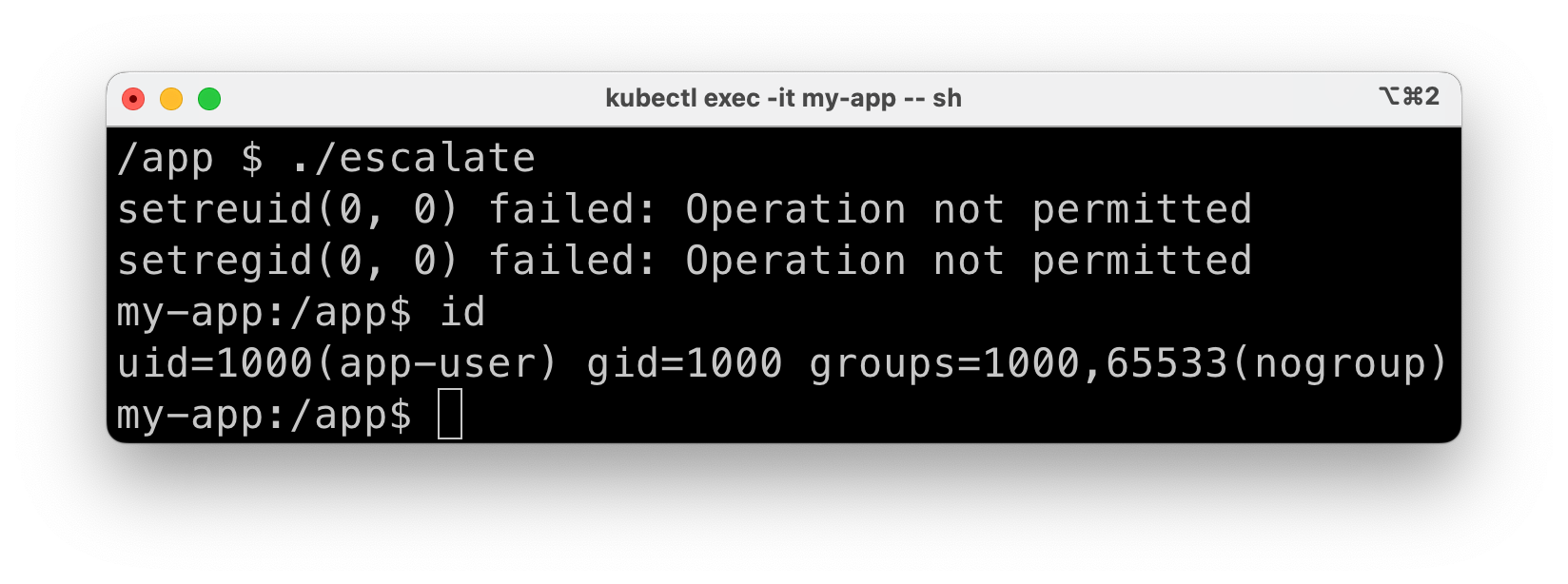
What happened? The calls to setreuid and setregid failed. Errors become more explicit if we add error handling to our “exploit” code:
// Escalate to root
if (setreuid(0, 0) != 0) {
printf("setreuid(0, 0) failed: %s\n", strerror(errno));
}
if (setregid(0, 0) != 0) {
printf("setregid(0, 0) failed: %s\n", strerror(errno));
}
How ‘allowPrivilegeEscalation’ works
Per the Kubernetes documentation:
AllowPrivilegeEscalation controls whether a process can gain more privileges than its parent process. This bool directly controls if the no_new_privs flag will be set on the container process.
The no_new_privs flag is a kernel feature introduced in 3.5 (released in 2012). When enabled, it ensures that no child process can gain more permissions than its parent.
We can confirm this behavior by manually setting no_new_privs before attemping to perform our privilege escalation, using a small utility program that:
- Uses the
prctlsystem call to setno_new_privs - Creates a new
shprocess, which will be “safe” against privilege escalation vulnerabilities.
We need this second step, because the newly set flag does not apply retroactively to our already-running shell process.
#include <string.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <sys/prctl.h>
int main(void) {
// Set no_new_privs
if (-1 == prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
printf("Could not set prctl: %s\n", strerror(errno));
}
// Spawn a shell
char* const argv[] = {"/bin/sh", NULL};
char* const environ[] = {"PATH=/bin:/sbin:/usr/bin:/usr/sbin", NULL};
if (-1 == execve("/bin/sh", argv, environ)) {
printf("Unable to execve /bin/sh, errno %d\n", errno);
}
}
When we compile and run this utility, we see that it’s properly setting the no_new_privs flag in our new shell process, as we can see by reading /proc/self/status:
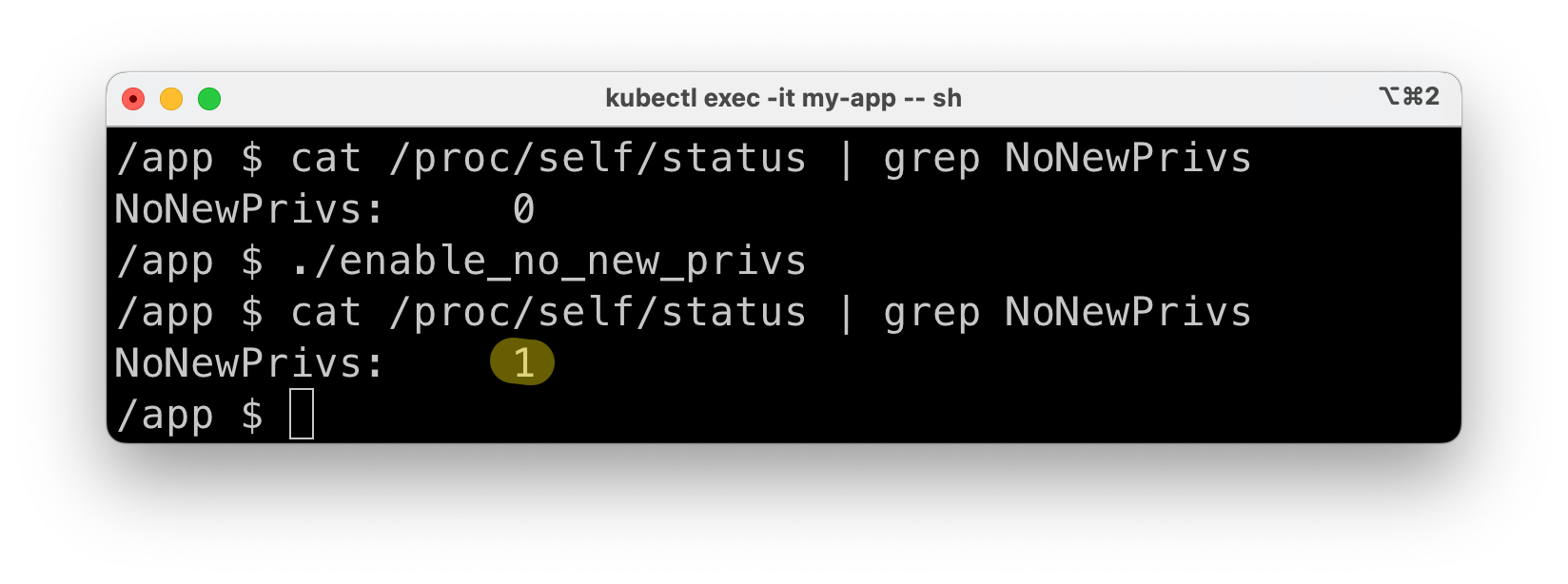
If we now attempt our privilege escalation again, notice how it’s now blocked—exactly as when we had set allowPrivilegeEscalation to false:
This little dance is exactly what the container runtime does when creating new containerized processes. For instance, here’s the container initialization code from runc, which is used by most container runtimes such as containerd, CRI-O, and Docker:
// if NoNewPrivileges is true (directly controlled by allowPrivilegeEscalation), then call prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0) [Editor's note]
if l.config.NoNewPrivileges {
if err := unix.Prctl(unix.PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0); err != nil {
return &os.SyscallError{Syscall: "prctl(SET_NO_NEW_PRIVS)", Err: err}
}
}
You can see that it’s performing the exact same process as we did:
- Check if
NoNewPrivilegesistrue(which is directly controlled by our Kubernetes security contextallowPrivilegeEscalationfield) - If that’s the case, turn on
no_new_privsbefore creating the container process.
So what’s the deal?
Security—like most disciplines that attempt to deal with systemic failures, is about building different layers to ensure that a single defect doesn’t turn into a data breach.
In this context: yes, explicitely turning off allowPrivilegeEscalation is a legitimate good security hardening practice. Turning it off greatly increases confidence that an attacker compromising an unprivileged application cannot escalate their privileges to root within the container, thus reducing the risk of exploiting further vulnerabilities that require root permissions.
Is it bad if you’re not turning it off on your workloads? Probably not. Consider it as (yet another) hardening mechanism that you haven’t enabled. It’s not what will get you hacked. Unless you’re a mature security team, you’re probably better off focusing on higher-value items for your container security roadmap at first (see my KubeCon EU 2024 talk and post for some threat-informed ideas about where to start).
That said, it’s not a setting you should ignore; make sure it’s part of your container security roadmap.
Frequently asked questions
What’s the default value for ‘allowPrivilegeEscalation’?
It’s true by default. See the related code and associated issue to make it clearer it in the docs.
Is there any point turning off ‘allowPrivilegeEscalation’ if my workloads run as root within containers?
No, there is absolutely no point. If your workloads run as root, there’s no further privilege escalation within the container they could achieve.
Is there any point turning off ‘allowPrivilegeEscalation’ if my workloads run as “privileged” or have the CAP_SYS_ADMIN capability?
No, there is no point. In fact, you cannot even do it—the API server will reject your request (see the related validation code):
The Pod "my-app" is invalid: spec.containers[0].securityContext: Invalid value: cannot set `allowPrivilegeEscalation` to false and `privileged` to true
Does turning off ‘allowPrivilegeEscalation’ protect against all sorts of privilege escalation within the container?
No. For instance, it wouldn’t help if an attacker exploits a kernel flaw that allows them to escalate their privileges. That said, it should block all privilege escalations that work by exploiting setuid/setgid.
Is there any link between ‘allowPrivilegeEscalation’ and ‘privileged’?
No. Turning off allowPrivilegeEscalation is a security hardening mechanism. If you leave it to its default value, processes within the container can still not trivially escalate their privileges, nor escape the container.
Running workloads with privileged enabled makes them run as if they were directly a process on the host, making container escape trivial by design.
Isn’t it the end of the world if an attacker manages to escalate to root within a container?
Yet another misconception, joyfully relayed by the FUD that sometimes drives the security industry. A process running as root inside the container cannot trivially escape outside of it. It would have to exploit another vulnerability or misconfiguration.
Conclusion
Hopefully, this post provided a deeper overview of what ‘allowPrivilegeEscalation’ is, what it is not, and the clear benefits of using it. I was confused myself when I first discovered it, and it seems to be a source of confusion for many people, perhaps due to its unfortunate naming.
Thank you for reading, and let’s continue the discussion on Hacker News, Twitter, or Mastodon!
Thank you to my colleague Rory McCune for reviewing this post.